消息隊列 - Apache Kafka
2023-09-20
/
在前一篇文章中,我介紹了消息隊列的概念以及其特性與優點。今天,我們將進一步研究一個業界廣泛應用的第三方消息隊列服務 - Apache Kafka。
前言
在前一篇文章中,我介紹了消息隊列的概念以及其特性與優點。今天,我們將進一步研究一個業界廣泛應用的第三方消息隊列服務 - Apache Kafka。
Apache Kafka 的起源
Apache Kafka 最初是由 LinkedIn 團隊開發,旨在解決資料傳遞問題。在 2011 年,Kafka 成為開源專案,並隨後捐獻給 Apache 基金會。目前,Kafka 主要由 Linkedin 與 Confluent (由 Linkedin 內部工程師創立,專為 Kafka 提供企業級支援的公司) 兩家公司持續維護與開發,並被許多大型知名公司所採用,包括 Netflix, Uber, Spotify 等
Apache Kafka
Apache Kafka 是一個使用 Scala 語言開發的開源事件串流平台。它採用分散式、多分區、多副本的發布訂閱架構,主要用於收集、處理和儲存串流事件資料
Apache Kafka 的組成
Apache Kafka 主要由以下幾個組件組成:
- 生產者 (Producer): 生產者創建訊息,並把消息發佈到主題中
- 消費者 (Consumer): 消費者訂閱主題,獲取並處理訊息
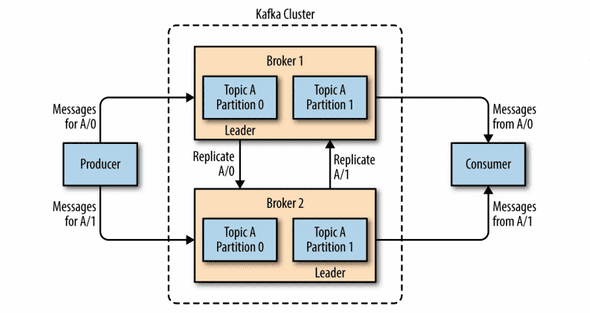
- 主題(Topic): 主題是一個不可變的事件日誌,用於儲存相關或相同類型的事件。生產者將事件寫入特定的主題,而消費者則從主題中讀取事件。主題可以被分成多個分區,以實現水平擴展和並行處理
- 分區(Partition):每個分區都是一個有序、不可變的事件隊列,分區允許多個消費者並行地讀取和處理訊息。每個分區都有一個唯一的識別符(Partition ID)
- Kafka 叢集(Kafka Cluster):Kafka 叢集是由多個 Kafka Broker 組成的集合。Kafka Broker 負責處理來自生產者和消費者的請求,並將數據寫入和讀取主題的分區。Kafka 叢集提供了高可用性和容錯能力,即使其中一個 Broker 失效,整個叢集也能繼續運行
Apache Kafka 的特性與優點
Apache Kafka 具有以下特性與優點:
高吞吐量、低延遲 Apache Kafka 是專為大數據串流處理而設計的,能夠每秒處理上百萬條訊息,具有高吞吐量和低延遲的特性。
高可擴展性 由於 Apache Kafka 採用分散式架構,因此可以通過增加 Kafka broker 的數量來實現水平擴展,並可以通過增加單個 Kafka broker 的容量來實現垂直擴展。
高資料可靠性、可用性 Apache Kafka 具有多分區的副本機制,在每個分區都可以有多個副本,提供了數據的備份,以防止故障和數據丟失
資料持久性 Apache Kafka 將資料輸出為記錄檔並儲存於硬碟空間,可以將數據持久化儲存,以便後續的批量處理或數據回放
Apache Kafka 的應用場景
由於 Apache Kafka 具有高可擴展性、高吞吐量和低延遲等特性,它特別適合用於大數據領域的實時計算與傳輸。因此,許多大型軟體公司都熱衷於使用它。此外,由於 Kafka 能夠持久化保存數據,它也常被用來處理日誌資料並分析瞭解使用者行為。
以下是一些使用 Kafka 處理資料的知名公司:
- Uber: Uber 使用 Kafka 來即時收集用戶、計程車和行程數據,用於計算和預測需求,並即時計算高峰定價。
- Spotify、Pinterest: Spotify、Pinterest 將 Kafka 作為其日誌收集管道的一部分
- Airbnb: Airbnb 使用 Kafka 進行事件處理及異常追蹤。
結論
Apache Kafka 是一個強大的事件串流平台,具有高吞吐、低延遲、高可擴展以及高可用性等特性,被許多大型公司所採用。然而,正如其他技術一樣,Apache Kafka 也有其缺點和挑戰。
- 路由彈性較低: 相較於 RabbitMQ 等其他消息隊列平台,Kafka 的路由彈性較低。Kafka 只匹配確切的主題名稱,並不支援萬用字元主題選擇
- 硬碟空間需求:因為 Kafka 的設計是將所有訊息持久化到硬碟,所以對硬碟空間的需求可能會隨著訊息的增長而急劇增加
- 大架構與操作複雜:Kafka 的架構相對大,且操作複雜,對於初學者來說可能有一定的學習曲線。這可能導致在實施和維護 Kafka 時需要更多的時間和資源。
儘管有這些挑戰,但 Apache Kafka 的優點和廣泛的應用場景使其成為大數據領域中的重要工具。總的來說,選擇是否使用 Apache Kafka,應根據具體的業務需求和組織能力進行評估。